I have been carrying out sobol analysis for global sensitivity analysis of a simple analytical model.
My understanding is the total sobol indices should sum to one and represent the contribution of the input parameter’s variance to the total variance of the property of interest.
I have noticed my total sobol indices often sum to more than 1. What could be causing this? Note my input parameters are not correlated at all.
Actually, the total Sobol’ indices will, in general, sum to more than 1. I think you might have mistaken the total Sobol’ indices for the first-order Sobol’ indices (whose sum cannot be larger than 1). The total Sobol’ index of an input parameter is the sum of the first-order Sobol’ index and all the higher-order Sobol’ indices involving that parameter.
So, if you sum the total indices, you would double count many indices. It is only for a special case that the sum of the total indices is 1. That is, if all the higher-order indices are 0; in other words, the sum of the first-order indices is 1. Note that this property is not about whether your inputs are correlated or not, but whether they are interacting with respect to the output.
Regarding this topic, the explanation from the Wikipedia article might be helpful:
Hi!
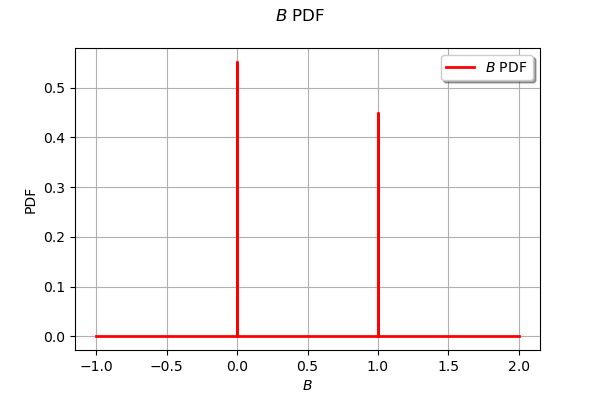
Just to further clarify the already excellent answer by @damarginal , although the sum of the first order indices cannot be greater than 1, their estimate can. This is because the sum of the first order indices is a random variable. Assuming that there are no interactions (so that the first order indice is equal to the total order indice), the exact sum is equal to 1. Now consider the random variable
B = 1 \textrm{ if } \sum_{i=1}^p \hat{S}_i > 1
and zero otherwise.
We have P(B=1)=1/2.
To check it, I created the linear model Y = 1 + 2X_1 + 3 X_2 + 4 X_3 where X_i\sim\mathcal{N}(0,1) and are independent. I used a sample size equal to 10000 to estimate Sobol’ indices with Saltelli estimator. I counted 1 if the event occurs, and 0 otherwise. Then I repeated the experiment 500 times. Here is the distribution of the 0/1 random variable:
We check that the probability of having an estimate sum larger than 1 is close to 0.5.
This is an interesting look at the estimates of the Sobol’ first-order sensitivity indices (that, of course, makes sense)! Thanks!
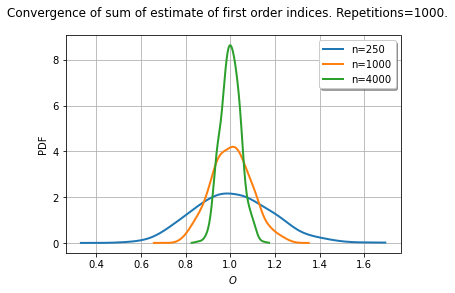
Based on the nice illustration you showed here, I assume that the sampling distribution (i.e., from the replications) of the first-order indices sum estimates would approximately be normal centered at 1.0 and that the spread of this distribution would become narrower and narrower with increasing number of sample points used in the estimation (or at least, I hope so). But there’s always roughly the same chance that the sum would be greater than 1.0 and the sum would be less (or equal) than 1.0. Is this correct?
Hi,
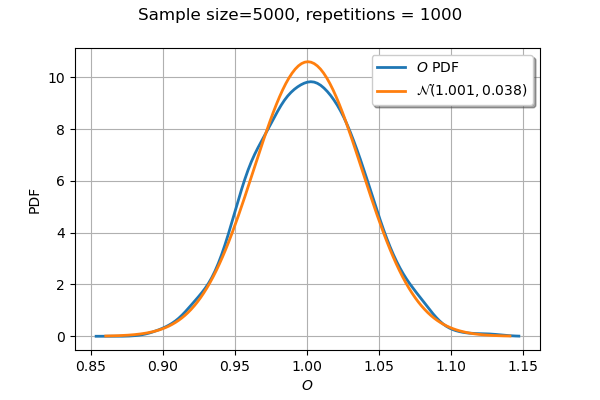
This is even more accurate. The distribution of the first order indices is asymptotically Gaussian, which can be seen from the delta-method. This is a distribution with dimension d, if there are d random inputs. Hence, the sum of its d marginals is normal. I never did this experiment, so I was too tempted to let it go.
Below is an experiment with a sample size equal to 5000, repeated 1000 times. The variable O (for “one”) is the sum of first order indices. I first estimate the distribution of the samples of O with kernel smoothing, then estimate the parameters of the normal. That fits very well.


 Thanks a lot for trying the experiment and posting the results here!
Thanks a lot for trying the experiment and posting the results here!