Introduction
The Black-box reliability benchmark was organized by TNO (Netherlands) under the lead of @rozsasarpi in the second part of 2019. It consists of a set of test reliability problems, for which the limit state function is not known to the user. The user can only run each function distantly on a server for a limited number of times. The server also counts the number of calls to the limit state function. The goal of the benchmark was to compare different methods used by different research groups in terms of accuracy (closeness to a reference solution) and efficiency (minimal number of calls to the limit state functions).
The Chair of Risk, Safety and Uncertainty Quantification participated in the benchmark and solved 26 different reliability problems, whose detailed definition is given here. Nine different research groups have participated anonymously to the benchmark.
Methodology
In our group, the benchmark was run by @moustapha, who developed a robust approach using PC-Kriging and subset simulation.
Results
The results are nicely summarized here on the official website, in which our team is “User 8”.
In the following plot (taken from the official website), we emphasize the performance of our UQLab approach.
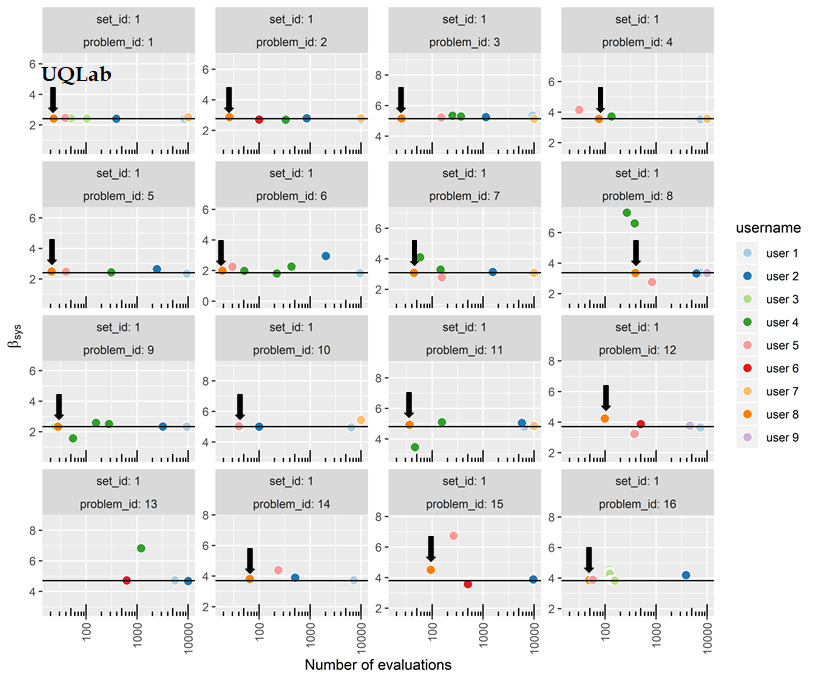
Figure 1: Results of the first set of benchmark problems (component reliability, i.e. single limit state function)
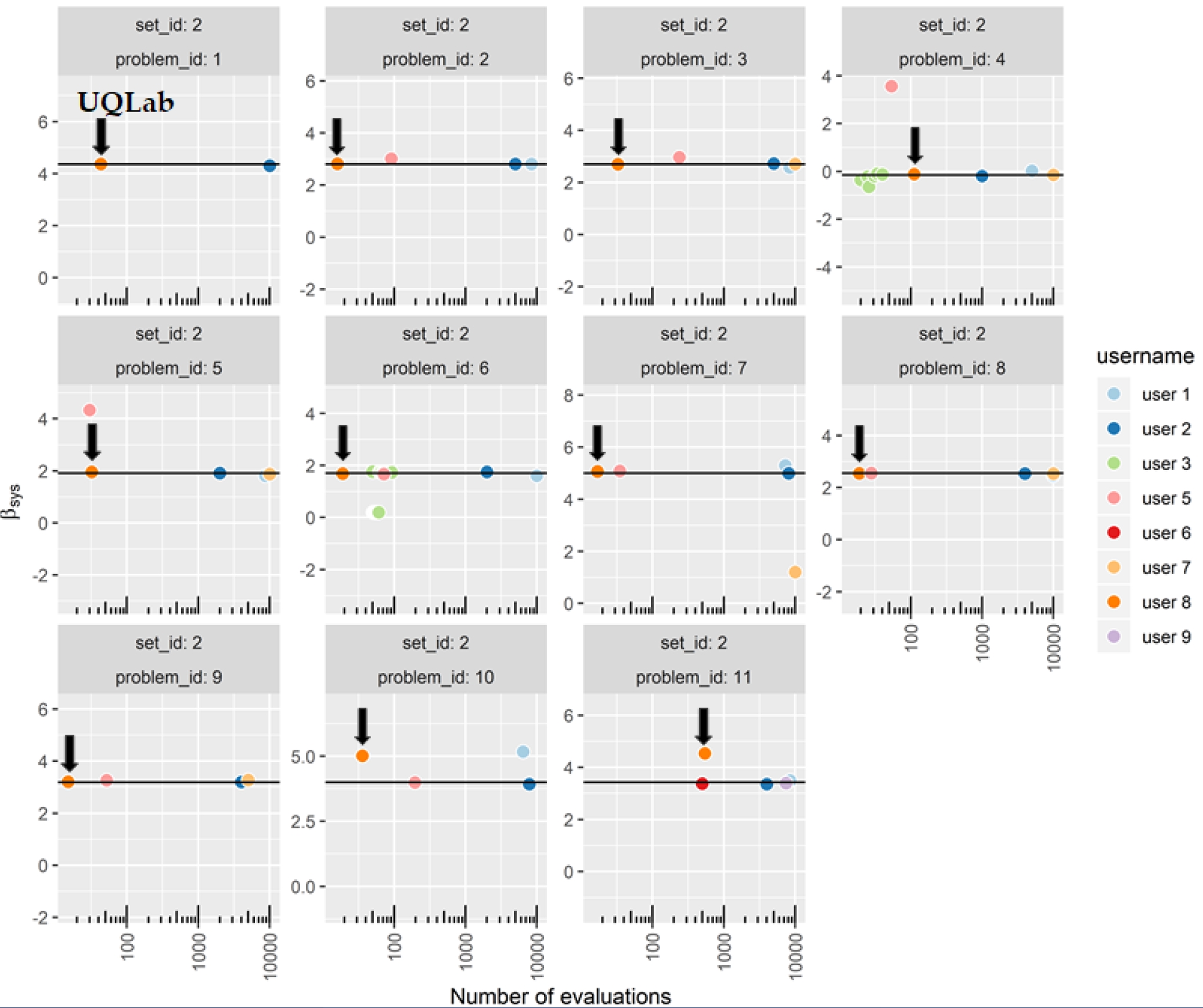
Figure 2: Results of the second set of benchmark problems (system reliability)
For each problem, the reference solution (reliability index \beta) is the black line. Each point with coordinates (number of calls, estimated \beta) correspond to a team participating in the benchmark.
Accurate methods correspond to points on the black line, while efficient methods correspond to the far left points in each subfigure.
We are very happy to observe that our results are very accurate for most problems (except the ones with extremely large reliability indices, i.e. greater than 4). In terms of efficiency, our approach is more (to far more) efficient than the competing methods for a vast majority of the solved problems.
Conclusions
The benchmark was also the occasion for us to develop a new general-purpose module for reliability analysis based on surrogate models and active learning techniques that will be released with the next version of UQLab V1.4. The published results also helped us to identify the problems for which our approach is suboptimal. We’re currently working on it!