Hi Charol,
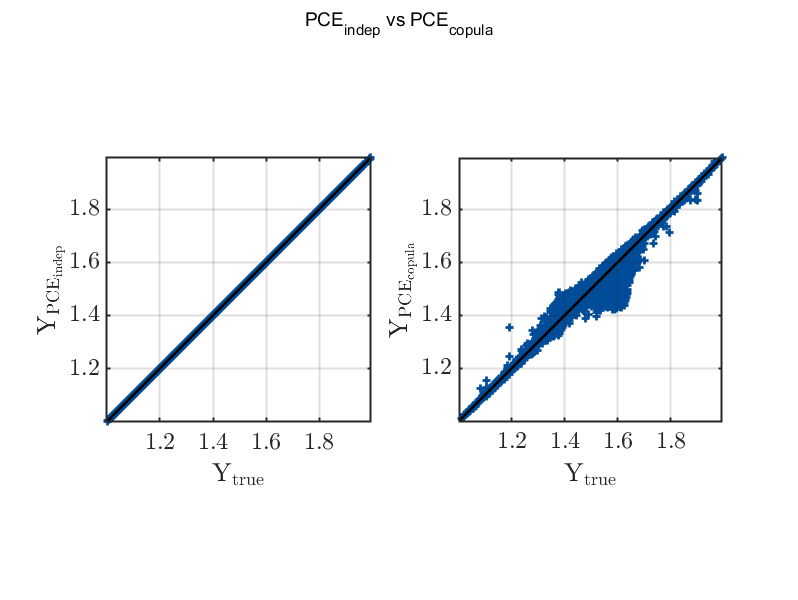
Yes, aPCEonX outperforms lPCEonZ regarding pointwise estimation. It is not clear in general which one yields better statistical estimates: For the Ishigami function, aPCEonX is better; for the horizontal truss, they perform similarly except for the standard deviation, where lPCEonZ performs slightly better. In general, if the pointwise convergence is good, then also the moments will be estimated well.
No, they are computed by propagating a large set of samples from the input distribution through the PCE models (Torre et. al. 2019, Section 3.1). It would not be possible to use the coefficients of aPCEonX to compute the moments, since in this case the basis functions are not orthonormal wrt the input distribution. For lPCEonZ it should be possible, but maybe the authors wanted to use the same computation method for both approaches to be comparable.
Regarding your plots: Yes, this can happen. The Ishigami function is very sparse in the Legendre polynomial basis. If you use the approach lPCEonZ, what you are actually surrogating is the Ishigami function combined with the inverse of the transformation from the dependent input X to independent standard variables Z:
\mathcal{M}_\text{lPCEonZ}(Z) = \text{Ishigami}(T^{-1}(Z))
The transformation T from dependent to independent standard variables can be highly nonlinear. It is possible that \mathcal{M}_\text{lPCEonZ} cannot be well approximated by polynomials anymore. It is also possible that \mathcal{M}_\text{lPCEonZ} is not sparse anymore in the PCE basis. This is not so critical when we have enough experimental design points available (i.e., many more points than unknown coefficients), since in this case we can use least-squares, but if we want to use sparse regression methods like LARS with few design points, non-sparseness can deteriorate the solution a lot.
Another view on this is the following: PCE work so well because engineering models are often smooth, close to polynomial, and follow the sparsity-of-effects principle (a heuristic saying that the most important terms have low interaction order). The engineering model does not know or care about what distribution the inputs have, it simply follows from the laws of physics (and some simplifications). If we now introduce the transformation from dependent to independent input variables, we change the model structure and might lose all these favourable properties. Imagine that for the same model, we try out several inputs, each with a different dependence structure. With the approach lPCEonZ, we would have to approximate totally different models each time, even though the physical mechanism is the same in all cases! This shows that also conceptually the approach aPCEonX might be more meaningful.
There are more open questions on this topic, e.g., which distribution should the training set be sampled from - from the dependent input distribution or from the product of the input marginals, corresponding to the distribution orthogonal to the aPCEonX basis functions?
If you come across interesting publications in this direction (PCE with dependent input variables), please share them with us!