First of all, I would like to thank the people who developed wonderful software.
Chemical engineer believe that designing with uncertainty is essential because there is uncertainty in the input data, which affects the quality of the product.
Originally, neural nets were used to predict product performance. But I was fascinated by PCE’s ability to derive similar predictive performance with a small dataset.
What I want to do is use PCE as a predictor for the black box model.
So I am studying using uqlab example.
Examples\Metamodelling\PCE\uq_Example_PCE_05_TrussDataset.m
In the X data used in the example above, the third row(A1) has a minimum value of 0.001513 and a maximum value of 0.002611.
In the example code, the variable A1 is saved as shown below.
InputOpts.Marginals(3).Type = ‘Lognormal’
InputOpts.Marginals(3).Moments = [2.0e-3 2.0e-4]
-
Can i know if the distribution is Lognormal by plotting the data? if the distribution of the data is not a known distribution like Lognormal or Gaussian, how do i enter the distribution?
-
I think Moments should be entered considering the maximum and minimum values of the data.
I am wondering why Moments is [2.0e-3 2.0e-4] in the above problem. -
[Additional question] Neural net trains the model with training data and evaluates the model with test data. In this example, do i think that the total of 10200 data is divided into 200 training data and 10000 test data? If yes, is there a ratio of dividing the number of data?
X 200 * 10 double, Y 200 * 1 double
Xval 10000 * 10 double, Y 10000 * 1 double
- [Additional question]
The average of Y is -0.0794. If we assume that the system is reliable when Y is less than -0.1, can i determine the condition of the input variables at that time?
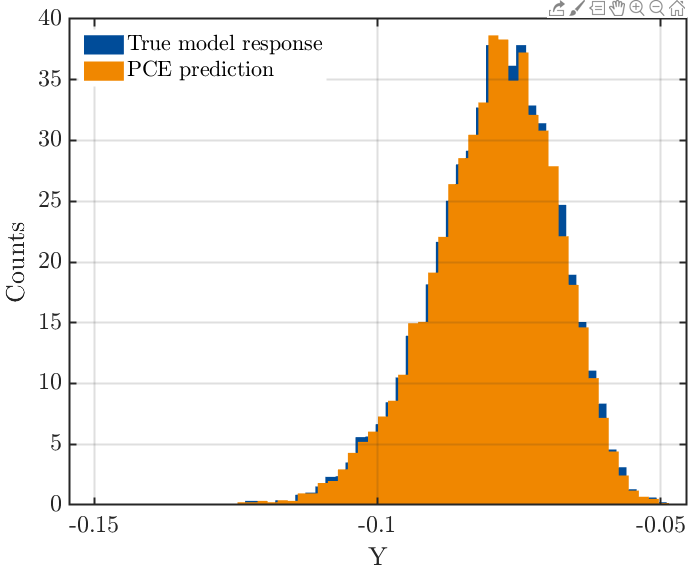
-
[Additional question] Neural nets can create new functions that approximate underlying functions through weights and biases, and can be optimized through those functions. Is it possible to optimize using PCE like this?
-
[Additional question] Is it possible to predict any single input data set using the PCE model?
(pointwise prediction)
[1, 2, 0,1 0.2]-> PCE Model-> [?]
(4 dimension input)
