Hello, all
I am recently doing a Bayesian calibration of the classical elongation problem. The case is simple: We apply a force P on the beam, then we get a displacement u. All other variables (E,L,b,h) are constants.
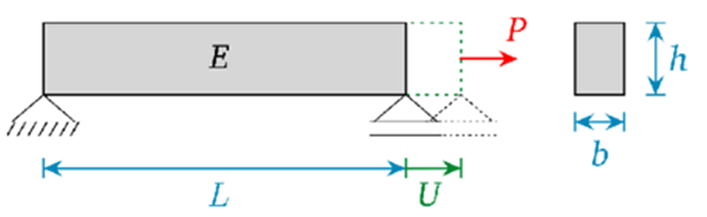
The inversion principle works as:
Forward model: \mathcal{M}(p): U = \frac{PL}{Ebh}
The likelihood is constructed by the discrepancy between observation u and forward model \mathcal{M}(p)
\mathcal{L} (p,\sigma \mid u) = \frac{1}{(2\pi)^{{3}/2}\det(\boldsymbol{\Sigma}(\sigma))^{1/2}} \exp\left(-\frac{1}{2}\left(u - \mathcal{M}(p)\right)^{\mathsf{T}} \boldsymbol{\Sigma}(\sigma)^{-1}\left(u - \mathcal{M}(p)\right)\right)
\Sigma(\sigma) = \sigma^2 I
The discrepancy \sigma^2 is usually unknown, it is common practice for \sigma^2 inferred together with model parameter P. This requires the initial specification of a prior distribution of the distribution parameter \pi(\sigma^2), which UQlab document and examples adopt the mean of the observation.
Here come to my question: Since the discrepancy \sigma^2 is the error between the observation u and forward model \mathcal{M}(p), why should we take the mean of the observation as a prior for \pi(\sigma^2)? Personally I think it is too big. Why not take 1%-5% of mean of the observation as a prior for \pi(\sigma^2)?
The reason I propose this question is because when I doing the elongation beam problem. If I take mean of observation u as a prior for \pi(\sigma^2). The result looks like this (not good):
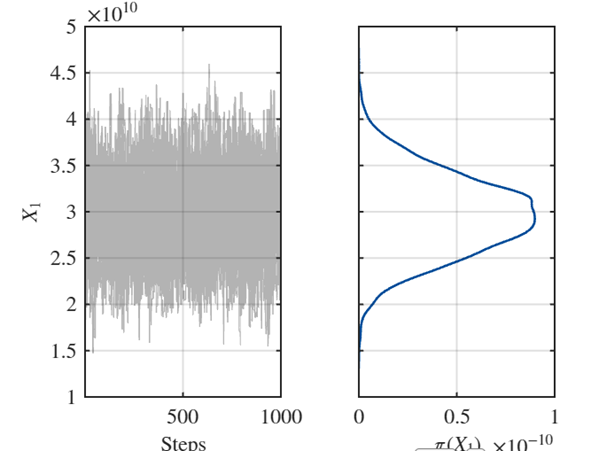
If I take 1% of mean of observation u as a prior for \pi(\sigma^2), the result looks like this (good):
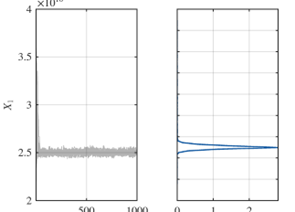
I understand the difference is from the setting of discrepancy \sigma^2, not from UQlab.
In summary: how can I determine a reasonable range for the discrepancy parameter \sigma^2? I understand that it must be related to the measurements u, but are there any rules for this? For instance, is 1%-5% of the measurement a reasonable range for a good prior for discrepancy? Because clearly, 1% of the measurement works perfectly for this elongation problem. But would this also apply to other, more general problems? I’m hoping to receive some guidance on this.
Any suggestions and comments will help
Best,
Ningxin