Hi, uqlab!
I have a question about sampling method.
First of all, i want training data driven based PCE metamodel.
So, i extract some data using LHS method.
But i don’t know how many number of data is needed.
- Set 98% accuracy as the target accuracy. (assume)
- Observe the accuracy by gradually increasing the number of samples starting with 50.
ex) 50 -> add 20 -> add 20 -> add 20 -> … -> add 20(accuracy : 99%) -> stop!!! - If the accuracy is satisfied, sample extraction is stopped.
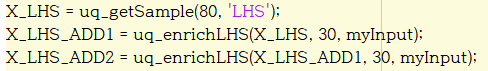
I want to do the adaptive sampling method as above, but I think uq_enrichLHS can be used. However, if you extract once more from the initial sample and extract it once more, the following error will appear.
The initial sample set does not form a Latin
Hypercube! For eniriching such set in a
pseudo-LHS fashion use uq_LHSify function
instead.
- I am curious about the exact difference between enrichLHS and LHSify and the principle of each method. Should I use LHSify for my research??
- Does uq_enrichLHS(X, N, myinput) always show better accuracy than uq_enrichLHS(X, N)?
- There are 6 input variables of data. Is there an optimal number of data depending on the dimension of the input variable?