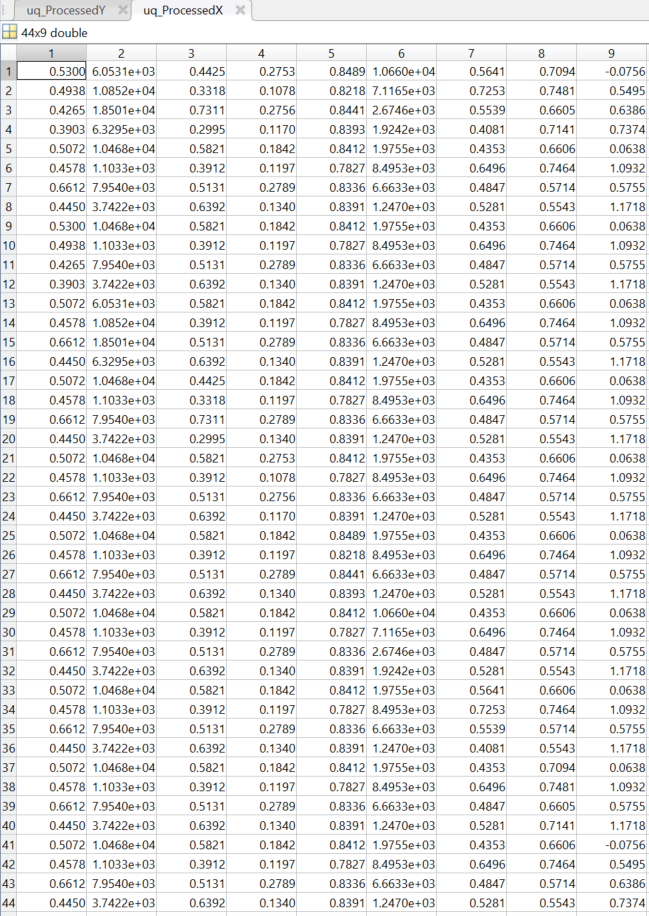
I have been using UQLab to run sensitivity studies on a large custom model written in Python. I have done so using both UQLink and a wrapper function (as described in the Model user manual). Now, for some combinations of input parameters my Python model fails to converge. This is desired as it provides insight into the feasibility of certain input parameter combinations, however, those failed model evaluations seem to prevent calculating the Sobol’ indices.
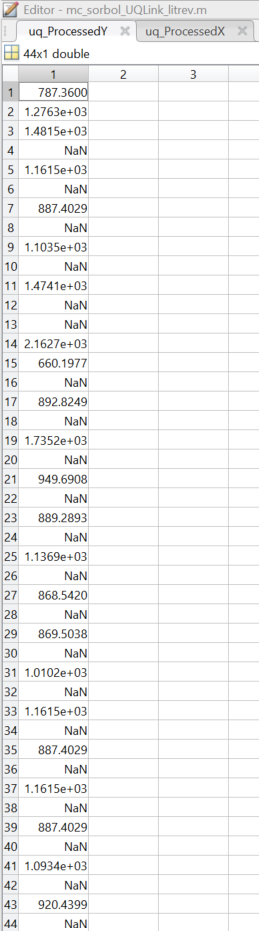
Now, I am not an expert in the field so I don’t know how these cases should be dealt with from a mathematical viewpoint, but in section 2.7.8 (‘Recovering failed results’) of the UQLink user manual it says that responses corresponding to failed simulations are set to NaN (as observed in ‘uq_ProcessedY’, a screenshot of which is attached). When trying to calculate the Sobol’ indices from the following code,
Error using uq_sobol_indices
Unable to perform assignment because the size of the left side is 1-by-9 and the size of the right side is 1-by-0.
Is this due to the fact that my ‘UQLinkOutput’ folder only contains the files corresponding to those evaluations which did not fail (see further attached screenshot)?
In summary, my question is whether I can still calculate calculate the Sobol’ indices despite some model evaluations failing?
Thanks for your interesting question. In fact, the probabilistic model for the input parameters should make sense from a physical point of view with respect to your computer code. Even if you choose uniform distributions, the bounds should be physical, and not leading to the crash of the code. Remember that you represent the input uncertainties as they would be in reality (be it because of natural variability or because of lack of detailed knowledge): this input modelling conditions all further analysis and can’t be done out of the blue. However, usually we know what the parameters mean and can at least give reasonable bounds.
If you are in a case where many combinations of inputs are nonsensical, then all the framework of UQ, especially sensitivity, does not apply. It would be OK if there are only a few crashes in thousands or millions of runs, but if you have a significant proportion, then you should rethink your input probabilistic model.
Assuming you’ll solve this, and referring now to your code snapshot, if you use 'Sobol' as a method for sensitivity analysis, the number of samples SobolOpts.Sobol.SampleSize must be much larger, typically \mathcal{O}(10^3), but certainly not 4.
If this is not feasible for computational costs, then you would need to first calibrate a surrogate model such as Kriging or polynomial chaos expansions. Which again requires that your input domain, from which an experimental design will be drawn to fit the surrogate, is physically well-defined.
Thank you very much for your comprehensive response! I will narrow down my probabilistic inputs to make sure the code doesn’t crash. Regarding the sample size of 4, I picked such a small number to test whether UQLink works, but I will ensure the sample size for my actual simulations is sufficiently large.
I have a follow-up question on this topic. In some cases, especially with a large parameter space, you have to give each parameter a fairly large physiological range. Also, there are times when the model fails in very specific, known, combinations (e.g., the model fails if k2 < k1, but k1 and k2 are parameters with a known physiological range: k1 = [0.1 0.5] and k2 = [0.3 0.7]).
Therefore, given the condition above or some other condition I hadn’t considered, the model will sometimes fail (less than 2% of the time). What can we do then to calculate Sobol indices?
Is there a way to manually enter the A and B matrix?